
Deep Learning 101
Deep learning has become something of a buzzword in recent years with the explosion of 'big data', 'data science', and their derivatives mentioned in the media. Justifiably, deep learning approaches have recently blown other state-of-the-art machine learning methods out of the water for standardized problems such as the MNIST handwritten digits dataset. My goal is to give you a layman understanding of what deep learning actually is so you can follow some of my thesis research this year as well as mentally filter out news articles that sensationalize these buzzwords.
Intro
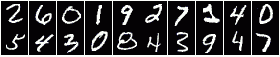
(source)
{kind=link}
Imagine you are trying to recognize someone's handwriting - whether they drew a '7' or a '9'. From years of seeing handwritten digits, you automatically notice the vertical line with a horizontal top section. If you see a closed loop in the top section of the digit, you think it is a '9'. If it is more like a horizontal line, you think of it as a '7'. Easy enough. What it took for you to correctly recognize the digit, however, is an impressive display of fitting smaller features together to make the whole - noticing contrasted edges to make lines, seeing a horizontal vs. vertical line, noticing the positioning of the vertical section underneath the horizontal section, noticing a loop in the horizontal section, etc.
Ultimately, this is what deep learning or representation learning is meant to do: discover multiple levels of features that work together to define increasingly more abstract aspects of the data (in our case, initial image pixels to lines to full-blown numbers). This post is going to be a rough summary of two main survey papers:
- Representation Learning: A Review and New Perspectives by Yoshua Bengio, Aaron Courville, and Pascal Vincent
- Deep Learning of Representations: Looking Forward by Yoshua Bengio
Why do we care about deep learning?
Current machine learning algorithms' performance depends heavily on the particular features of the data chosen as inputs. For example, document classification (such as marking emails as spam or not) can be performed by breaking down the input document into bag-of-words or n-grams as features. Choosing the correct feature representation of input data, or feature engineering, is a way that people can bring prior knowledge of a domain to increase an algorithm's computational performance and accuracy. To move towards general artificial intelligence, algorithms need to be less dependent on this feature engineering and better learn to identify the explanatory factors of input data on their own.
Deep learning tries to move in this direction by capturing a 'good' representation of input data by using compositions of non-linear transformations. A 'good' representation can be defined as one that disentangles underlying factors of variation for input data. It turns out that deep learning approaches can find useful abstract representations of data across many domains: it has had great commercial success powering most of Google and Microsoft's current speech recognition, image classification, natural language processing, object recognition, etc. Facebook is also planning on using deep learning approaches to understand its users1. Deep learning has been so impactful in industry that MIT Technology Review named it as a top-10 breakthrough technology of 20132.
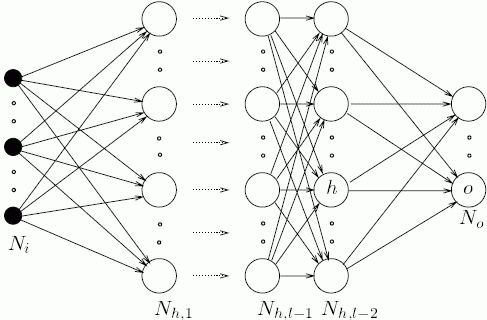
So how do you build a deep representation of input data? The central idea is to learn a hierarchy of features one level at a time where the input to one computational level is the output of the previous level for an arbitrary number of levels. Otherwise, 'shallow' representations (most current algorithms like regression or svm) go directly from input data to output classification.
One good analogue for deep representations is neurons in the brain (a motivation for artificial neural networks) - the output of a group of neurons is agglomerated as the input to more neurons to form a hierarchical layer structure. Each layer N is composed of h computational nodes that connect to each computational node in layer N+1. See the image below for an example:
(source)
{kind=link}
Interpretations of representation learning
There are two main ways to interpret the computation performed by these layered deep architectures:
- Probabilistic graphical models have nodes in each layer that are considered as latent random variables. In this case, you care about the probability distribution of the input data x and the hidden latent random variables h that describe the input data in the joint distribution p(x,h). These latent random variables describe a distribution over the observed data.
- Direct encoding (neural network) models have nodes in each layer that are considered as computational units. This means each node h performs some computation (normally nonlinear like a sigmoidal function, hyperbolic tangent nonlinearity, or rectifier linear unit) given its inputs from the previous layer.
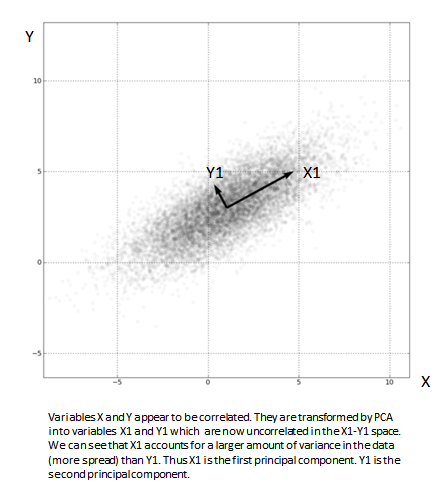
To get started, principal component analysis (PCA) is a simple feature extraction algorithm that can span both of these interpretations. PCA learns a linear transform h = f(x) = WT x + b where W is a weight matrix for the inputs x and b is a bias. The columns of the dx x dh matrix W form an orthogonal basis for the dh orthogonal directions of greatest variance in the input training data x. The result is dh features that make representation layer h that are decorrelated.
(source)
{kind=link}
From a probabilistic viewpoint, PCA is simply finding the principal eigenvectors of the covariance matrix of the data. This means that you are finding which features of the input data can explain away the most variance in the data3.
From an encoding viewpoint, PCA is performing a linear computation over the input data to form a hidden representation h that has a lower dimensionality than the data.
Note that because PCA is a linear transformation of the input x, it cannot really be stacked in layers because the composition of linear operations is just another linear operation. There would be no abstraction benefit of multiple layers. To form powerful deep representations, we will look at stacking Restricted Boltzmann Machines (RBM) from a probability viewpoint and nonlinear auto-encoders from a direct encoding viewpoint.
Probabilistic models: restricted boltzmann machine (RBM)
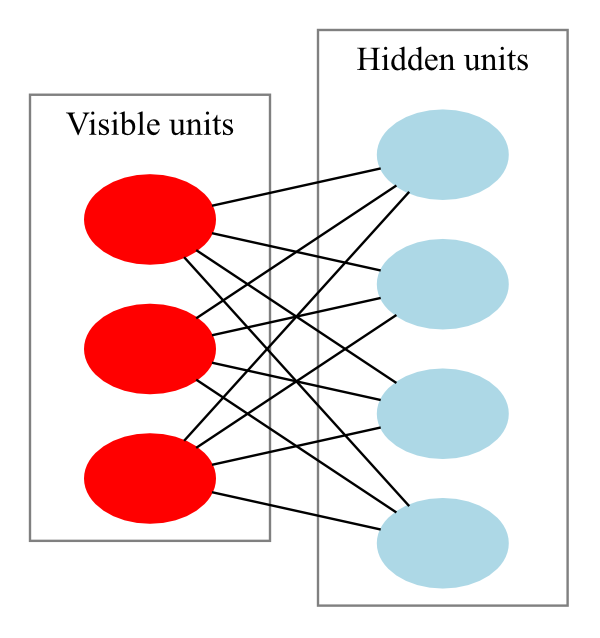
A Boltzmann machine is a network of symmetrically-coupled binary random variables or units. This means that it is a fully-connected, undirected graph. This graph can be divided into two parts:
- The visible binary units x that make up the input data and
- The hidden or latent binary units h that explain away the dependencies between the visible units x through their mutual interactions.
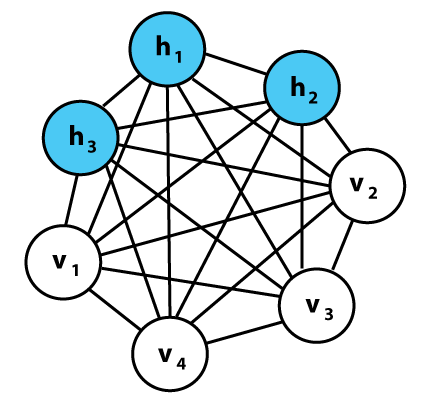
(A graphical representation of an example Boltzmann machine. Each undirected edge represents dependency; in this example there are 3 hidden units and 4 visible units. source)
Boltzmann machines describe this pattern of interaction through the distribution over the joint space [x,h] with the energy function:
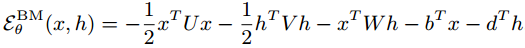
Where the model parameters Θ are {U,V,W,b,d }.
Trying to evaluate conditional probabilities over this fully connected graph ends up being an intractable problem. For example, computing the conditional probability of hidden variable given the visibles, P(hi | x), requires marginalizing over all the other hidden variables. This would be evaluating a sum with 2dh - 1 terms.
However, we can restrict the graph from being fully connected to only containing the interactions between the visible units x and hidden units h.
(source)
{kind=link}
This gives us an RBM, which is a bipartite graph with the visible and hidden units forming distinct layers. Calculating the conditional distribution P(hi | x) is readily tractable and now factorizes to:
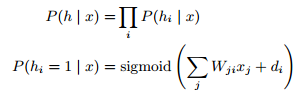
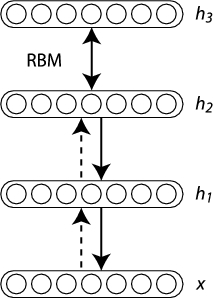
Very successful deep learning algorithms stack multiple RBMs together, where the hiddens h from the visible input data x become the new input data for another RBM for an arbitrary number of layers.
There are a few drawbacks to the probabilistic approach to deep architectures:
- The posterior distribution P(hi | x) becomes incredibly complicated if the model has more than a few interconnected layers. We are forced to resort to sampling or approximate inference techniques to solve the distribution, which has computational and approximation error prices.
- Calculating this distribution over latent variables still does not give a usable feature vector to train a final classifier to make this algorithm useful for AI tasks. For example, we calculate all of these hidden distributions that explain the variations over the handwriting digit recognition problem, but they do not give a final classification of a number. Actual feature values are normally derived from the distribution, taking the latent variable's expected value, which are then used as the input to a normal machine learning classifier, such as logistic regression.
Direct encoding models: auto-encoder
To get around the problem of deriving useful feature values, an auto-encoder is a non-probabilistic alternative approach to deep learning where the hidden units produce usable numeric feature values. An auto-encoder directly maps an input x to a hidden layer h through a parameterized closed-form equation called an encoder. Typically, this encoder function is a nonlinear transformation of the input to h in the form:
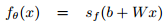
This resulting transformation is the feature-vector or representation computed from input x.
Conversely, a decoder function is used to then map from this feature space h back to the input space, which results in a reconstruction x'. This decoder is also a parameterized closed-form equation that is a nonlinear 'undoing' the encoding function:
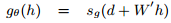
In both cases, the nonlinear function s is normally an element-wise sigmoid, hyperbolic tangent nonlinearity, or rectifier linear unit.
Thus, the goal of an auto-encoder is to minimize a loss function over the reconstruction error given the training data. Model parameters Θ are {W,b,W',d }, with the weight matrix W most often having 'tied' weights such that W' = WT .
Stacking auto-encoders in layers is the same process as with RBMs:
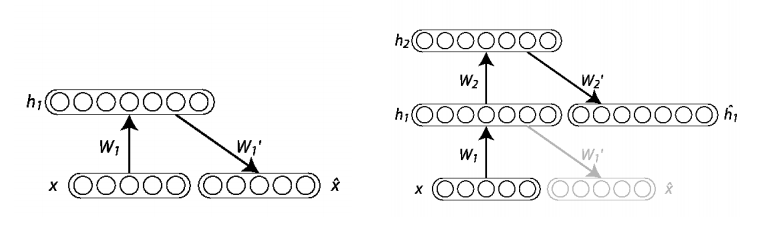
One disadvantage of auto-encoders is that they can easily memorize the training data - i.e. find the model parameters that map every input seen to a perfect reconstruction with zero error - given enough hidden units h. To combat this problem, regularization is necessary, which gives rise to variants such as sparse auto-encoders, contractive auto-encoders, or denoising auto-encoders.
A practical advantage of auto-encoder variants is that they define a simple, tractable optimization objective that can be used to monitor progress.
Challenges and looking forward
Deep learning is currently a very active research topic. Many problems stand in the way of reaching more general AI-level performance:
Scaling computations - the more complex the input space (such as harder AI problems), the larger the deep networks have to be to capture its representation. These computations scale much worse than linearly, and current research in parallelizing the training algorithms and creating convolutional architectures is meant to make these algorithms useful in practice. Convolutional architectures mean that every hidden unit output to a layer does not become the input for every other hidden unit in the next layer; they can be restricted to only connect to other hidden units that are within the same spatial area. Further, there are so many hyper-parameters for these algorithms (number of layers, hidden units, nonlinear functions, training procedures) that choosing them has become considered an 'art'.
Optimization - as the input datasets grow larger and larger (growing faster than the size of the models), training error and generalization error converge. Optimization difficulty during training of deep architectures comes from both finding local minima and having ill-conditioning (the two main types of optimization difficulties in continuous optimization problems). Better optimization can have an impact on scaling computations, and is interesting to study to obtain better generalization of the algorithms. Layer-wise pretraining has helped immensely in recent years for optimization during training deep architectures.
Inference and sampling - all probabilistic models except for the RBM require a non-trivial form of inference (guessing values of the latent variables h given the conditional distribution over x). Inference and sampling techniques can be slow during training as well as have difficulties since the distributions can be incredibly complex and often have a very large number of modes.
Disentangling - finding the 'underlying factors' that explain the input data. Complex input data arise from the interaction of many interrelated sources - such as lights casting shadows, object material properties, etc. for image recognition. This would allow for very powerful cross-task learning, leading to a representation that can 'zoom in' on the relevant features in the learned representation given the current problem. Disentanglement is the most ambitious challenge presented so far, as well as the one with the most far-reaching impact towards more general AI.
Conclusion
- Deep learning is about creating an abstract hierarchical representation of the input data to create useful features for traditional machine learning algorithms. Each layer in the hierarchy learns a more abstract and complex feature of the data, such as edges to eyes to faces.
- This representation gets its power of abstraction by stacking nonlinear functions, where the output of one layer becomes the input to the next.
- The two main schools of thought for analyzing deep architectures are probabilistic vs. direct encoding.
- The probabilistic interpretation means that each layer defines a distribution of hidden units given the observed input, P(h | x).
- The direct encoding interpretation learns two separate functions - the encoder and decoder - to transform the observed input to the feature space and then back to the observed space.
- These architectures have had great commercial success so far, powering many natural language processing and image recognition tasks at companies like Google and Microsoft.
If you would like to learn more about the subject, check out this awesome hub or Bengio's page!
If you are inclined to use deep learning in code, Theano is an amazing open-source Python package developed by Bengio's LISA group at University of Montreal.
Update: HN discussion